-
[Kafka] 카프카란? 개념과 디자인[IT] 공부하는 개발자/Data engineering 2020. 4. 11. 11:16
차례
카프카란
카프카는 서비스간에 메시지 통신을 제공하는, 메시지 큐 서비스이다. 실 서비스에서 언제 메시지 통신이 요구될까? 하나의 프로젝트로 기능하던 것을 여러개의 프로젝트로 쪼개서 배치되어있는 상황을 생각해보자. 이 때 각각의 도메인들은 내부에서 동적으로 요청을 처리한 후 다른 도메인에 그 결과를 전달해주어야 할 상황들이 있을 것이다. 즉 카프카와 같은 메시지 큐는 마이크로 서비스 아키텍쳐(MSA)를 구현하는 아키텍쳐 및 대량 데이터를 처리하는 분산시스템과 잘 어울린다.
카프카의 특징
디스크에 메시지 저장
카프카가 기존의 메시징 시스템들과의 다른 특징 중 하나는 디스크에 메시지를 저장하고 유지한다는 것이다. 카프카는 정해져 있는 보관 주기 동안 디스크에 메시지를 저장해둔다.
분산 시스템
같은 역할을 하는 여러 대의 서버로 분산 처리 기능을 제공한다. 분산 시스템을 구현하면 하나의 서버에 장애가 발생해도 다른 서버가 장애 서버의 역할을 대신함으로써 장애상황에 대응할 수 있고, 트래픽을 여러 서버들이 분산하여 가짐으로써 대량 트래픽에 대응할 수 있다. 비용 면에서도 스케일업 보다는 스케일아웃이 더 적은 비용이 든다. 카프카 클러스터는 최소 3대의 브로커에서 수십대의 브로커까지 확장이 가능하다.
페이지 캐시
카프카는 JVM을 사용하는 애플리케이션으로 메시지 처리는 JVM에 할당된 메모리를 이용하여 이루어진다. 그리고 이와 별도로 I/O은 페이지 캐시를 이용하여 처리하는데, I/O 를 할 때마다 매번 새로 시작하는 대신 캐시를 유지하여 작업을 한다면 시간을 절약할 수 있기 때문이다. 즉 카프카에서 Heap 메모리를 할당할 때에는 물리 메모리를 전부 할당해서는 안 되고, 이 페이지 캐시부분 메모리를 감안하여 적당한 양을 할당하여야 한다.
KAFKA_HEAP_OPTS = "-Xmx4G -Xms4G"(덧붙임) Heap 메모리를 할당할 때 어떤 GC 알고리즘을 사용하고 있는지도 고려하여야 하는데, 최신 알고리즘인 G1 GC의 경우 Major GC가 일어 날 때 Application Stop 없이 다중 스레드가 메모리 개간을(Reclaim) 진행한다고 알려져 있으므로 많은 메모리를 설정하여도 Application Stop 이 일어나지 않는다. 하지만 그 이하 버전 CMS GC, Parallel GC의 경우 Major GC를 수행할 때 다른 스레드들은 모두 멈추고 Single Thread 가 GC를 수행하므로 Heap Memory 가 너무 크면 Application Stop 시간이 길어지게 된다. 이는 동시간의 서비스 지연을 의미하기 때문에, 이 경우 너무 큰 Heap Memory를 부여하는 것은 추천하지 않는다. 또한 Max Heap Memory와 Minimum Heap Memory 는 동일하게 설정하는 것이 프로덕션 환경에서 Best Practice로 굳어져 있는데, 미니멈에서 맥시멈 사이의 메모리를 조정하는 과정에서 자원이 소모되기 때문에 애초부터 동일하게 설정하는 것이 자원 절약의 관점에서 좋기 때문이라고 한다.
배치 전송 처리
데이터를 주고받을 때는 I/O가 필연적으로 발생하게 되는데, 이 I/O는 자원을 상당히 많이 소모하는 작업이다. 따라서 I/O 비용을 줄이기 위하여, 카프카는 하나하나의 메시지마다 I/O를 실행시키는 것이 아니라 메시지가 쌓이기를 기다려 여러건을 모았다가, 배치작업에 의해 일괄적으로 I/O를 실행시켜 네트워크 왕복 오버헤드를 줄여준다.
카프카 데이터 모델
동작 방식
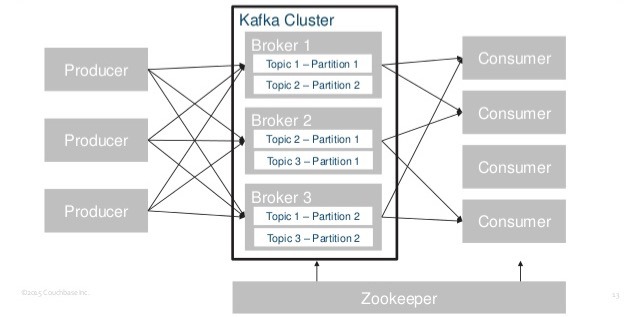
카프카 시스템 아키텍쳐 카프카는 기본적으로 메시징 서버이다. 메시지를 보내는 쪽은 퍼블리셔 혹은 프로듀서(Publisher, Producer)라고 부르고 메시지를 가져가는 측은 컨슈머(Consumer)라고 부른다. 중앙에 메시징 시스템 서버를 두고 메시지를 Publish 하고 Subscribe 하는 형태의 Pub/Sub 모델을 채용하고 있다. 카프카 서버는 브로커(Broker)라고 명칭한다.
토픽
카프카 클러스터는 토픽이라는 단위로 데이터를 구분하여 저장한다. 가령 회사에 발주 부서와 배송 부서가 나뉘어져 있다고 생각해보자. 발주 부서 개발자들은 발주 토픽에 메시지를 발행하고 배송 부서 개발자들은 배송 토픽에 메시지를 발행한다. 내가 발주 부서의 메시지를 받아보고 싶다면 발주 부서의 토픽를 구독하여 컨슘한다.
토픽 이름은 249자 미만,영문, 숫자, '.', '-', '_' 를 조합하여 생성할 수 있다.
파티션
병렬처리
붐비는 야구장에서 화장실을 이용하기 위해 줄을 서본적이 있는가? 화장실 칸이 많다면 금방 금방 화장실을 이용할 수 있지만, 화장실 칸이 적다면 수많은 인원이 오랫동안 화장실을 사용하기 위해 기다려야 할 것이다.
파티션은 화장실의 각각의 칸과 같다고 생각하면 된다. 토픽이 처리해야 할 메시지의 수가 많을 경우, 메시지 속도를 높여주기 위하여 토픽의 파티션을 늘려준다. 파티션을 늘릴 경우 병렬 처리 방식으로 동시에 토픽의 메시지 발행, 컨슘이 가능하다. 다만 메시지를 발행하는 프로듀서의 숫자도 파티션만큼 늘려줘야 효율적이다. 파티션은 4개인데 메시지는 2곳에서만 들어온다면 소용이없다.

4개의 파티션이 4명의 컨슈머에게 메시지 전송 자, 그럼 파티션 수를 무조건 많이 늘리는 것이 능사일까?
꼭 그렇지는 않다. 이유는 아래와 같다.
1. 각각 파티션은, 할당된 파티션을 관리하는 브로커에 맵핑이 되게 되는데, 파티션의 수가 많다면 브로커가 매번 처리해야하는 리소스가 많아진다. 데이터가 저장될 때마다 모든 파티션에 대해 파일 핸들 처리를 해주어야 하기 때문이다.
2. 장애 복구 시간이 증가한다. 파티션 묶음을 관리하는 브로커에 장애가 생기면, 컨트롤러는 장애가 생긴 브로커가 관리하는 파티션들에 대해 모두 다음 리더 선출 작업을 해주어야한다. 파티션이 많으면 많을 수록 이 작업시간이 길어지게 된다.
파티션 수의 가장 이상적인 값은 프로듀서와 컨슈머 수에 맞춰 설정하는 것이다. 프로듀서 서버를 4개 운용한다면 파티션은 4개가 적절할 것이고, 컨슈머 서버가 8개라면 8개도 고려할 수 있다.
순서보장
파티션간의 순서보장을 이해하기 위해 화장실에 줄 서기 비유를 다시 사용해보자. 변기가 10칸 있고 10개의 줄이 있는 화장실을 생각해 보자. 나와 영희는 각각 다른 줄에 섰고 민지는 나랑 같은 줄로 내 뒤에 섰다. 앞 사람들의 변기 사용 속도(컨슘 속도 ㅎㅎ)에 따라 옆 줄에 선 영희보다 내가 더 늦게 들어갈 지, 일찍 들어갈지는 알 수 없다. 그래도 내 줄 안에서의 순서는 확실히 알 수 있다. 같은 줄에서 뒤에 선 민지보다 내가 무조건 빨리 들어간다.
우리가 만약에 변기가 한 칸만 있는 화장실에 간다면 100% 순서보장이 될 것이다. 화장실에 변기가 한 칸만 있어서 줄이 1개이면, 그 줄의 순서가 곧 사용 순서가 된다. 즉 카프카를 사용하면서 꼬오오옥 순서보장을 해야 한다면 파티션을 1개만 사용하면 된다. (다만 칸이 10개인 화장실보다 더 붐비는 것은 어쩔 수 없을것이다...)
파티션과 컨슈머
하나의 파티션에는 하나의 컨슈머만 연결될 수 있다. (화장실 한 칸에 줄이 2개가 생기면 더 혼란스럽고 부작용을 초래한다.)
오프셋
프로듀서가 발행한 메시지는 선입선출로 (FIFO) 메시지 큐에 저장된다. 이 때, 저장된 순서에 따라 인덱스 번호를 가지게 되는데, 이를 카프카에서는 오프셋(Offset)이라고 한다. 카프카는 이 오프셋을 이용해 메시지 순서를 보장한다.

이 인덱스 번호는 고유한 값일까?
답은, "그렇기도 하고 아니기도 하다" 이다.
각각의 파티션에서 인덱스 번호는 유일한 값으로 고유하지만, 토픽기준으로 봤을 때 인덱스 값은 파티션의 개수만큼 존재할 수 있으므로 고유하지 않다.
카프카 리플리케이션
분산 처리 애플리케이션인 카프카는 특정 서버에 물리적 장애가 발생하는 경우에도 대응할 수 있도록 리플리케이션 기능을 제공한다. 메시지파티션을 복제하여 여러 브로커에 나누어 저장하는 것이다.
지금부터 총 2개의 동일 파티션을 갖는 (1개가 리플리케이션 되는) 카프카 디자인을 상상해보자. 먼저 config에서 기본값인 1로 설정되어있는 replication factor 를 2로 바꾸어 준다.
$ vi /usr/local/kafka/config/server.properties ### default.replication.factor = 2그러면 이제 모든 토픽의 파티션들은 별도로 하나의 복제 파티션을 더 가진다. 파티션은 2개의 브로커들에 각각 저장되어 있어서, 리더 파티션이 있는 브로커에 장애가 일어나더라도 복제된 팔로워 파티션이 있는 브로커가 살아 있으므로 메시지가 유실되지 않을 수 있다. (아래 그림 참조) 리더와 팔로워는, DB의 Master DB와 Slave DB와 같은 개념으로 이해하면 된다. 리더는 모든 읽기와 쓰기 작업을 관리하는 파티션이고 팔로워는 리더의 데이터를 리플리케이션만 하는 파티션이다. 리더 파티션에 장애가 생기면 팔로워 파티션은 리더로 승격될 수 있다.

리플리케이션 팩터가 2인 카프카 시스템 디자인이다. ISR은 리더 1개+팔로워 1개=총 2개 파티션으로 구성된다. 이 리더와 팔로워들이 속해있는 리플리케이션 그룹을 ISR(In Sync Replica)이라고 부른다. 리더는 팔로워의 이상을 주기적으로 감지하여 팔로워를 ISR에서 추방시키는 역할을 한다. 다만 새로운 팔로워를 새로 데려오는 것은 리더가 하지 않는다. 브로커의 컨트롤러가 한다.
ISR 파티션들이 모두 다운 된 후에 복구할 때에 필요한 조건은 무엇일까? 바로 리더 파티션이 떠야 한다는 것이다. 팔로워 파티션은 모종의 사유로 리더 파티션에서 데이터 복제를 다 받지 못했을 가능성도 있기 때문에, 데이터 유실을 막기 위해서 반드시 리더 파티션이 살아나야 해당 파티션이 정상화된다.
다음 포스팅에서는 로컬에서 카프카 브로커를 기동하고, 토픽 생성, 발행, 컨슘하는 법을 다룬다.
다음 글 보기
2020/05/07 - [[IT] 공부하는 개발자/Open Source] - [Kafka] 터미널에서 카프카 토픽 생성, 발행, 컨슘하기
[Kafka] 터미널에서 카프카 토픽 생성, 발행, 컨슘하기
목차 1. 카프카 설치 2. 토픽 생성 3. 프로듀서 실행 / 메시지 발행 4. 컨슈머 실행 / 메시지 컨슘 1. 카프카 설치 준비물 // Git, Docker 가 PC에 설치되어 있어야 한다. 먼저 깃으로 kafaka-docker 를 설치한다...
gem1n1.tistory.com
https://gem1n1.tistory.com/221
[Kafka] 카프카의 실전 서비스 운영
2020.02.15 - [[IT] 공부하는 개발자/Open Source] - [Kafka] 카프카란? 개념과 디자인 [Kafka] 카프카란? 개념과 디자인차례 카프카란 카프카의 특징 카프카 데이터 모델 카프카 리플리케이션 카프카란 카프
gem1n1.tistory.com
'[IT] 공부하는 개발자 > Data engineering' 카테고리의 다른 글
스파크 - 성능 최적화하기, 리팩토링 practice (0) 2023.02.26 스파크는 무엇이고 왜 쓰는지? 스파크에 대해 알아보기 (0) 2023.02.26 [R 회귀분석 예제] 야구선수 연봉에 영향을 미치는 요인 (Linear Regression) (3) 2020.06.21 [쉽게 설명하는 머신러닝] 머신러닝 문제 정의, 알고리즘 선택 방법 (0) 2019.05.26 [쉽게 설명하는 머신러닝] 개념 정리 (0) 2019.05.25